Nello sviluppo e nella validazione di trading system è prassi suddividere i dati a disposizione in due blocchi: In Sample, anche detto Training Set, E Out of Sample, anche detto Test Set. Il fine di questa operazione è quello di creare le condizioni che ci permettano di misurare, in fase di validazione, la qualità dei segnali individuati dal modello. Premesso infatti che in fase di sviluppo si è creato un trading system che sul blocco In Sample produce risultati ritenuti accettabili (secondo i nostri obiettivi di rischio/rendimento), resta da capire come e in quale misura il sistema andrà ad aumentare questo rapporto quando utilizzato per generare segnali su dati in tempo reale.
Qual’è la maniera più corretta di effettuare questo confronto IS/OOS? E’ sufficiente un esame “visivo” (qualitativo) della porzione di equity line In Sample rispetto a quella Out Of Sample o è possibile recuperare una certa oggettività di giudizio, misurando tale somiglianza?
Nel proseguo dell’articolo cerchiamo di rispondere a questa domanda, ma prima di spiegare il significato dell’analisi qui accanto, dobbiamo recuperare alcuni concetti chiave…
Componente di Segnale e di Rumore
Ritrovare consistenza fra il risultato In Sample e Out Of Sample dipende da quale componente dei movimenti del prezzo il sistema utilizza per generare i segnali; le due componenti in cui vogliamo scomporre il prezzo, nel caso in esame, sono il SEGNALE e il RUMORE.
In questo senso intendiamo che il prezzo si muove secondo due grandezze: un movimento di fondo chiamato segnale, che si ripresenta con una certa sistematicità, e un movimento casuale chiamato rumore. Un trading system deve cercare di individuare il primo, ignorando il secondo.
Sono numerosi gli esempi in cui osserviamo reazioni a un determinato scenario che sono statisticamente prevedibili: il riempimento dei gap di apertura sull’indice Standard & Poor’s 500, oppure i classici bias stagionali sulle commodities.
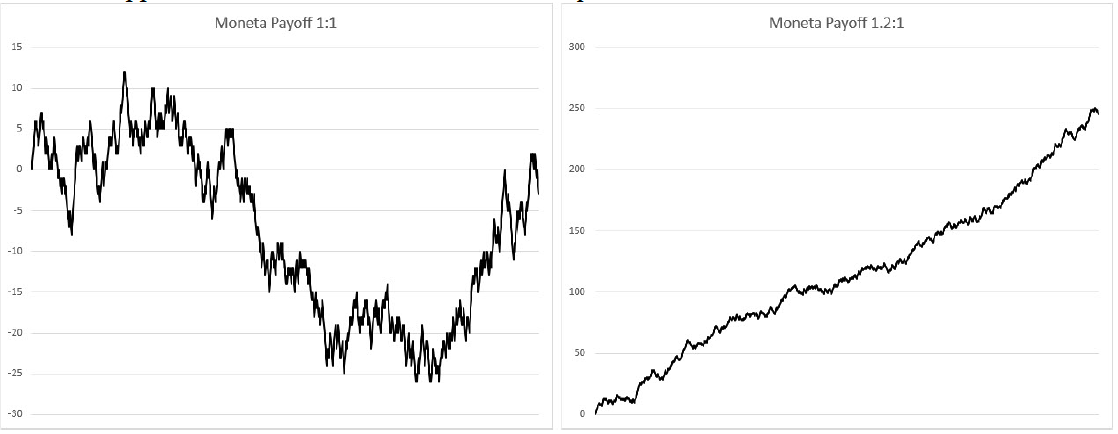
Figura 1 Payoff a confronto: Il risultato ottenuto da una successione di 1000 lanci di una monetina, con due differenti Payoff.
Un trading system, per essere profittevole, deve cogliere una finestra di prevedibilità nel comportamento del mercato. Ovvero deve essere in grado di generare segnali il cui esito, associato a un payoff medio, sul lungo termine sviluppi un guadagno.
Si nota come la scommessa Browniana della moneta con payoff 1 a 1, indipendentemente da quando decidiamo di accettarla e quando no, non può generare reddito. Tuttavia, dato un set di scommesse passate, è possibile creare un trading system che ci dica, considerando le ultime N scommesse, se prendere o non prendere la prossima. Creando un trading system dipendente da un numero sufficientemente elevato di variabili, nella ricerca del set di parametri migliore da utilizzare si navigherà uno spazio abbastanza ampio da contenere almeno una combinazione in grado di mostrare un rendimento molto importante.
Tuttavia noi sappiamo che, per costruzione, la serie su cui il sistema interviene non è prevedibile, e abbiamo quindi l’assoluta certezza che il risultato ottenuto non sarà replicabile in futuro.
La componente di rumore dei prezzi è in tutto e per tutto assimilabile all’andamento di una scommessa su una moneta con payoff 1 a 1. Essa ha una distribuzione simmetrica gaussiana ed è quindi completamente inutile nello sviluppo di un modello volto all’estrazione di profitto dal mercato. Ma, come nel caso della moneta, è possibile e anzi estremamente facile creare un trading system che su un set di dati sia in grado di mostrare un alto tasso di predittività ma sappiamo, tuttavia, che il rumore della serie non ha un sottostante prevedibile e quindi il sistema non ha possibilità di mostrare comportamenti analoghi su dati mai visti. In queste situazioni si parla di over-fitting (o sovra-ottimizzazione).
Ora, nel trading la situazione è un po’ più complessa, e a meno di commettere errori banali (esistono infatti numerose modalità con cui è possibile ridurre il rischio di overfitting) il comportamento del nostro trading system sarà sempre basato su un mix di rumore (la componente casuale) e di segnale (la componente predittiva).
Per comprendere la natura e le proporzioni di questa mix, l’unico modo, è quello di verificare il comportamento del trading system su dati diversi da quelli di sviluppo, da qui la definizione dei due blocchi di dati, In Sample (IS, detto training set dove viene appunto addestrato il sistema) e Out of Sample (OOS, detto test set, dove appunto viene testa il sistema su dati mai visti),
Essendo la componente di rumore imprevedibile (come nella scommessa sull’esito del prossimo lancio della moneta con payoff 1 a 1), il profitto su di esso generato sui dati Out of Sample si trasformerà in un andamento erratico non direzionale a cui si sommerà l’andamento del segnale.
Se la componente di segnale è sufficientemente forte e presente nella miscela del trading system, il sistema in esame mostrerà rendimenti in Out of Sample soddisfacenti.
In figura 2 e 3 andiamo a scomporre e mostrare questa miscela.
In Figura 2, con le due linee verdi e una rossa, vediamo l’andamento In Sample del nostro sistema: a sinistra il profitto generato attraverso la componente di rumore, in centro quello attraverso il segnale, e in rosso a destra la somma delle due.
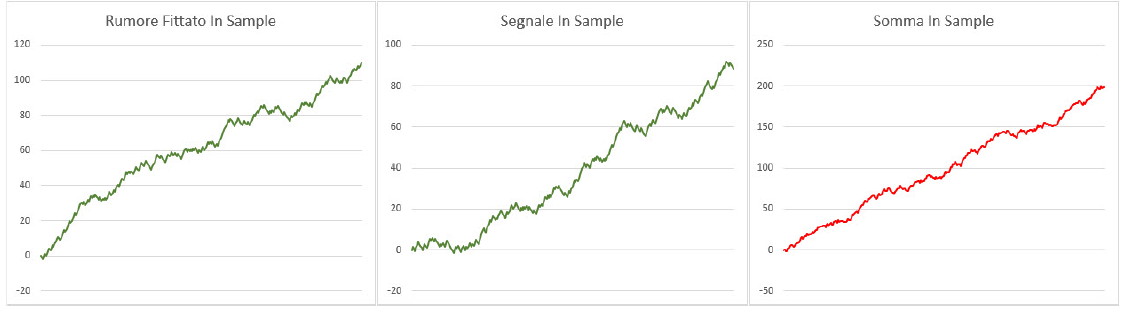
Figura 2, Scomposizione Segnale / Rumore (IS): La scomposizione delle componenti di segnale e rumore sulla porzione In Sample dei dati a disposizione.
In Figura 3, con le due linee blu e una rossa, mostriamo invece la scomposizione delle due componenti nella porzione Out of Sample. Guardando le due linee rosse, ovvero l’effettivo rendimento totale del sistema, notiamo chiaramente il degrado delle performance in Out of Sample a causa del venir meno della componente di fitting sul rumore. Ciò nonostante si vede come la componente di segnale sia sufficientemente importante da compensarne la mancanza e a mantenere un profilo ragguardevole sulla risultante.
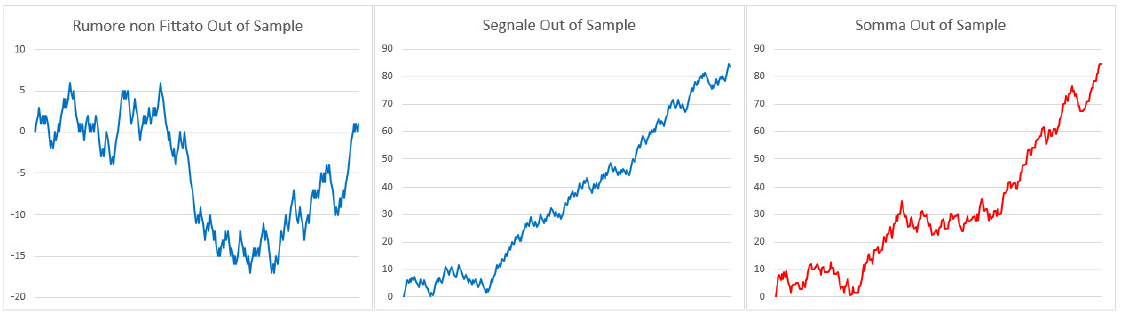
Figura 3, Scomposizione Segnale / Rumore (OOS): La scomposizione delle componenti di segnale e rumore sulla porzione Out Of Sample dei dati a disposizione, dove si osserva il degrado delle prestazioni dovuto all’incapacità del modello di continuare a operare sulla componente di rumore.
Quella appena mostrata è la situazione ideale.
Tutt’altro che ideale è invece la situazione in cui questa miscela fosse sbilanciata in favore del rumore, come mostrato in Figura 4. Qui si vede come il risultato generato nella porzione In Sample fosse interamente dovuto alla componente di rumore e non alla componente prevedibile e persistente di segnale. L’inevitabile incapacità di modellare il rumore su dati non visti in fase di sviluppo fa venir meno questa componente dominante di rumore (quella su cui si era fittato il sistema e che lo faceva guadagnare) e dunque ha provocato, in Out of Sample, questo degrado nelle performamce del sistema.
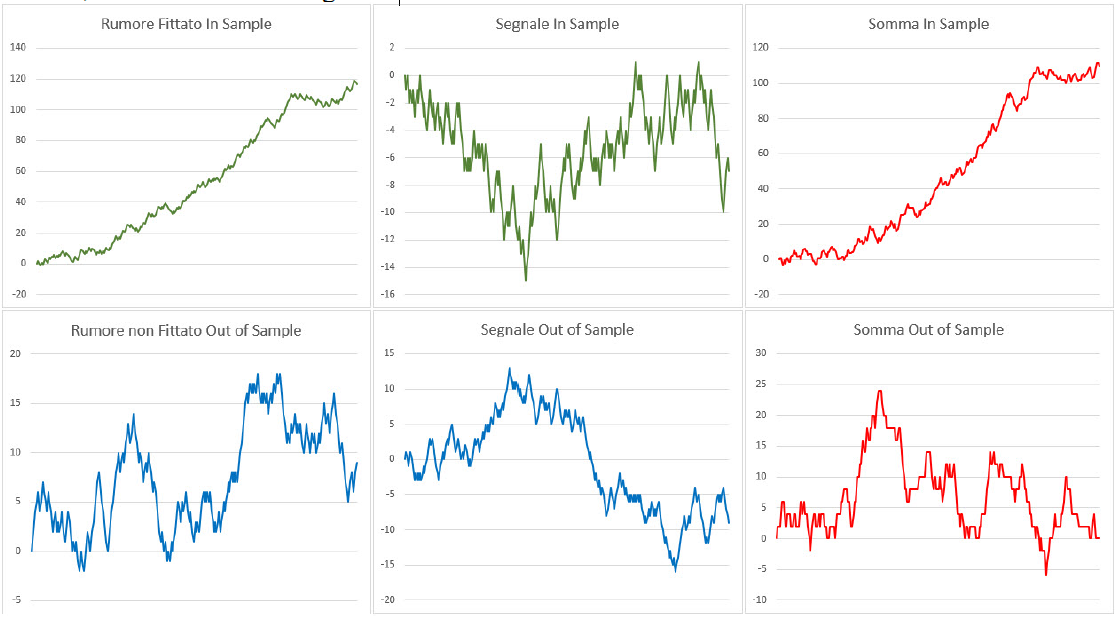
Figura 4, Scomposizione Segnale / Rumore e degrado delle prestazioni: La scomposizione delle componenti di segnale e rumore passando da IS a Out Of Sample: se sui dati IS si è intercettato solo la componente di rumore, nella porzione Out Of Sample i risultati saranno deludenti
Questo è quello che viene definito un modello caratterizzato da forte overfitting.
Purtroppo è molto complesso creare un sistema capace di cogliere un segnale dai movimenti di uno strumento; si stima infatti che i prezzi si muovano per il 95% del tempo come Moti Browniani.
Individuare un edge sul mercato richiede una conoscenza approfondita dello strumento e la capacità e l’esperienza necessarie a evitare le trappole dell’overfitting. Al contrario è molto semplice creare un sistema che fitti il rumore (è un banale esercizio di forza computazionale), motivo per cui nei trader alle prime armi si sviluppa facilmente l’errata convinzione che non sia possibile sviluppare modelli (meccanici) profittevoli.
Il processo appena mostrato di scomposizione di un equity line nelle sue componenti di rumore e segnale, purtroppo, non può essere eseguito in maniera inversa: non è possibile, da un’equity line, risalire e separare le sue componenti di segnale e rumore. Se lo fosse il nostro lavoro sarebbe estremamente più semplice.
Come facciamo, dunque, a stabilire se i risultati Out of Sample sono “compatibili” con i risultati In Sample?
Validazione con un T-Test di Student su un Trading System reale
Esistono una moltitudine di approcci, qualitativi e quantitativi, volti a questo scopo. Essendo nel trading non note la stragrande maggioranza delle variabili, è difficile stabilire quali delle assunzioni di questi metodi siano più o meno forti, e determinare quindi quale approccio sia il più affidabile.
Questi approcci sono attrezzi in possesso del trader che, usati con cura e cognizione di causa, possono essere molto utili e permettono di stabilire in anticipo quale sistema sia degno di un effettivo tentativo di utilizzo e quale no. Di seguito presentiamo uno di questi possibili approcci.
Si considerino le due coppie di linee rosse (In Sample e Out of Sample) delle figure precedenti.
Si può dedurre che l’overfitting del sistema non è elevato qualora non sia possibile rigettare l’ipotesi che i trade che hanno generato le due equity line provengano dalla stessa popolazione.
Se infatti potessimo rigettare questa ipotesi, e potessimo concludere che la distribuzione di origine delle due linee fosse diversa, si potrebbe giungere alla conclusione, essendo la componente di segnale prevedibile, che la miscela dell’equity line In Sample era prevalentemente spostata verso il rumore, la mancanza del quale ha provocato quindi un importante cambiamento nell’andamento del sistema in Out of Sample. Da cui l’overfitting.
Si faccia attenzione sul fatto che non poter rigettare un’ipotesi non implica il poterla accettare.
Non possedere sufficiente evidenza statistica da poter dire con una certa confidenza che due distribuzioni sono diverse, non suggerisce che esse siano uguali.
Questo è importante perché ci conduce ad utilizzare questo test come in generale si usano i backtest: non servono a stabilire se e quanto un sistema guadagnerà, ma a stabilire se un sistema abbia o meno il potenziale di guadagnare, e scartare dunque quelli che non ce l’hanno.
Per questo esempio utilizzerò un trading system reale, che lavora break out su Gold Future, che è stato sviluppato alla fine del 2012. Dalla primavera del 2013 questo trading system è pubblico, dato che è una delle 5 strategie che mettiamo a disposizione (a codice aperto) nel corso “Trading Automatico” (replicato 3 volte all’anno, da allora). Questa scelta, quindi, va nella direzione di dipanare ogni dubbio nel lettore sull’effettiva suddivisione delle porzioni di dati IS e OOS (in questo caso, quello che chiamiamo Out Of Sample sono più di 5 anni di operatività live).
In Figura 5 è possibile esaminare il fascio di equity line ottenute facendo variare i parametri liberi di questa strategia in un intorno dei valori che possono assumere, nel periodo che va dal 2003 al 2013 (In Sample).
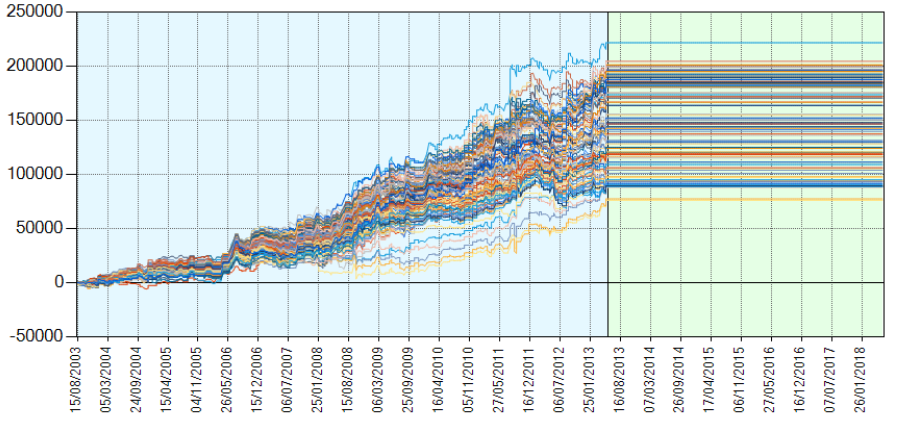
Figura 5, Il fascio di Equity In Sample del Trading System su Gold Future: Le equity line ottenute sulla porzione In Sample facendo variare i parametri liberi del trading system breakout su Gold Future.
Un primo esame visivo delle equity line relative ai diversi set di parametri indica che il sistema è pronto per un’analisi dei risultati sulla parte di dati Out of Sample, dal 2013 al 2018 (che qui sopra è la porzione con sfondo verde, dove, quindi, non so ancora come si sia effettivamente comportato il trading system).
Verifichiamo anzi tutto, qualitativamente, la tenuta dell’ipotesi di normalità. Sulla sinistra, in figura 6, vediamo gli istogrammi dei campioni di trade: quello colorato è l’istogramma del campione Out of Sample, quello posteriore con il solo contorno nero è l’istogramma dei trade In Sample.
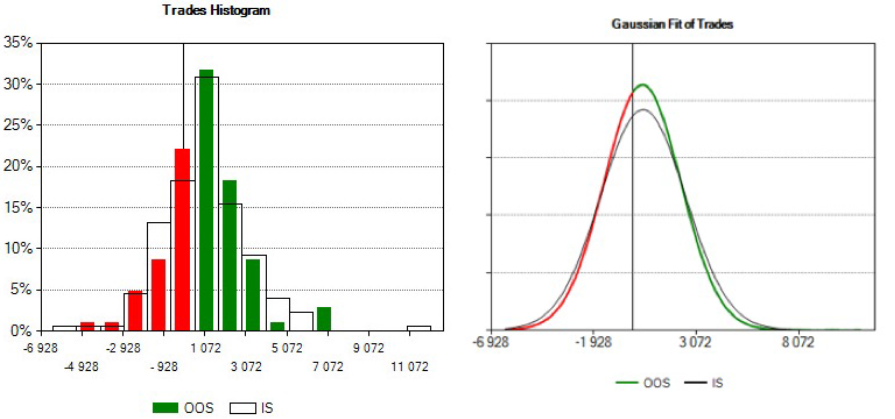
Figura 6, Verifica di Gaussianità dei Trade: Esame della distribuzione dei trade nelle porzioni In Sample e Out Of Sample per verifcare la gaussianità e procedere con il confronto
Sulla destra vediamo invece il relativo fit gaussiano. Vediamo che i due fit si comportano in modo simile ai relativi istogrammi, e vediamo inoltre che l’errore dell’ipotesi di gaussianità è orientato verso una leggera sovrastima del rischio al ribasso, e a una sottostima del potenziale al rialzo. Ripetiamo questa analisi su altre equity ottenute facendo fluttuare i paremetri liberi del trading system in un intorno dei valori scelti nella fase di addestraento (In Sample).
Stabiliamo dunque che l’ipotesi di fondo non è eccessivamente forte e che possiamo quindi proseguire. Il lettore, qualora lo ritenesse necessario, potrebbe proseguire con il disegno di un qq-plot o con un test di Shapiro come ulteriori forme di verifica di gaussianità. Già dagli istogrammi e dalle curve precedenti si intravede la somiglianza delle distribuzioni di origine, ma proseguiamo comunque nella ricerca di una risposta quantitativa.
Prima di allontanare il trader da quello che potrebbe sembrare un’analisi di difficile realizzazione, è meglio premettere che tutte queste immagini sono state prese dalla piattaforma StrategyLAB dove è possibile lanciare questi test con un semplice click. L’idea alla base di questa piattaforma è quella di rendere semplice e alla portata di tutti, delle analisi piuttosto sofisticate da realizzare ma altrettanto utili.
Fatta questa premessa, utilizziamo quindi un T-Test di Student per campioni indipendenti nel quale non si assume uguale varianza. Per questo test richiediamo una bassa confidenza (qui al 90%): questo significa che sarà sufficiente una minore evidenza statistica affinchè sia possibile rigettare l’ipotesi che i due set di trade provengano dalla stessa distribuzione. Se richiedessimo una confidenza maggiore, poniamo del 99.9%, sarebbe estremamente difficile rigettare questa ipotesi, producendo un test troppo semplice da passare. Si tratta quindi di una scelta conservativa e improntata alla cautela.
In figura 7 vediamo, per ognuno dei backtest relativi a ognuno dei possibili set di parametri del trading system (abbiamo fatto variare ogni parametro libero, su un intorno del valore scelto), la confidenza limite oltre cui è possibile rigettare l’ipotesi del T-Test. Solo per una ristretta parte dei backtest (quella con sfondo rosso) è possibile, con il 90% di confidenza, rigettare l’ipotesi di provenienza dalla medesima distribuzione (in particolare, è possibile rigettare l’ipotesi, per soli 7 test dei 1512 dell’ottimizzazione, ovvero lo 0.5% del totale: con un 90% di confidenza il 10% dei test avrebbe dovuto, come falso positivo, ricadere al di la della soglia del 90% per casualità. Che ciò accada solo nello 0.5% dei casi è molto promettente.)
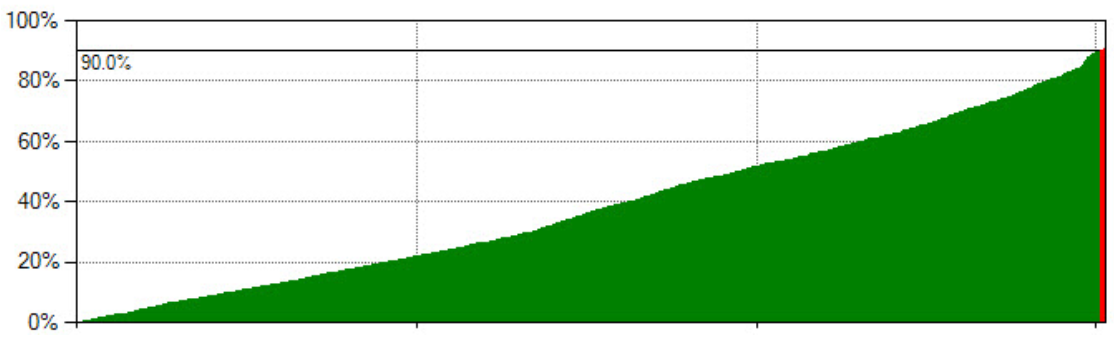
Figura 7, Risultato del T-Test di Student: Solo per una ristrettissima parte dei backtest (7 su 1512, la porzione rossa a destra) è possibile, con il 90% di confidenza, rigettare l’ipotesi di provenienza dalla medesima distribuzione.
Entro questo intervallo di confidenza (del 90%), possiamo quindi affermare che le operazioni effettuate dal trading system su dati In Sample e quelle effettuare su dati Out Of Sample, appartengano alla stessa famiglia, ovvero che la maggior parte delle combinazioni di parametri testate qui, abbia prodotto trading system che hanno intercettato una componente di segnale che continua a dare indicazioni corrette.
Questa tendenza è riscontrabile anche nel comportamento del sistema nella parte Out of Sample dei dati, e nel suo rimanere, per la maggior parte dei set di parametri, all’interno delle soglie di previsione costruite sui dati In Sample (un esempio dell’evoluzione Out Of Sample di una delle equity line della strategia, in Figura 8).
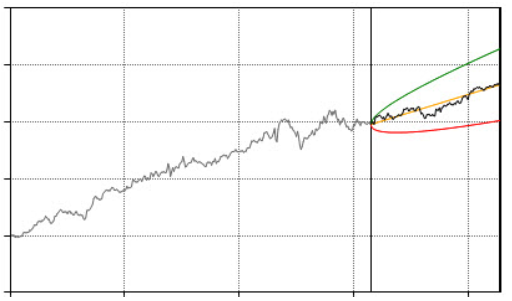
Figura 8, L’andamento Out Of Sample di una delle equity del Trading System su Gold Future: Dalla linea verticale è possibile esaminare come si è comportata una delle possibili equity delle 1512 analizzate, nel periodo Out Of Sample. Solo 7 su 1512 hanno fallito il T-Test, confermandoci l’affidabilità della strategia proposta.
Abbiamo qui mostrato come poter misurare con uno dei test che può effettuare la piattaforma StrategyLAB, se i trade prodotti dal sistema sui dati In Sample non siano troppo diversi da quelli prodotti sui dati Out of Sample. Abbiamo proposto un approccio quantitativo la cui unica assunzione è la gaussianità dei trade, assunzione che può essere più o meno forte a seconda del trading system e dello strumento su cui lo si è applicato, e che abbiamo mostrato come poter verificare.
Luca Giusti è un trader sistematico su Opzioni e su Futures dal 2002. Laurea in Economia, Dottorato di Ricerca in Direzione Aziendale, fondatore del progetto QTLab (Quantitative Trading LAB) in Svizzera, dove sviluppa metodologie di trading quantitativo. E’ advisor di due istituzionali e collabora con una software house (Da Vinci Fintech) con cui sviluppa piattaforme di analisi di dati finanziari, di backtest di strategie in Opzioni e di analisi di Portafogli (StrategyLAB e OptionLAB). Autore del libro “Trading Meccanico”, edito da Hoepli, Socio Ordinario Professional e docente del Master SIAT, è al suo secondo mandato come membro del comitato scientifico di questa associazione. E’ il docente dei corsi di QTLab sui Trading System e sull’Operatività con le Opzioni. Dal 2008 è relatore all’ITForum e al Tol EXPO di Borsa Italiana, è stato speaker al convegno internazionale IFTA 2017, relatore per TradeStation a Dubai nel 2016 su dei corsi di Trading Sistematico, e speaker in un convegno del CME Group a Londra nel 2019.